

Enkele jaren geleden was het nog al Big Data wat de klok sloeg, ondertussen weten we eindelijk wat we met al die gegevens moeten doen: modellen trainen. Waar machine learning en deep learning tot voor kort nog het terrein waren van bedrijven als IBM en Google, of van hippe nieuwe tech start-ups, wordt de technologie nu ook toegankelijk voor andere bedrijven. Maar wat is dat eigenlijk, deep learning?
Wie enkele jaren geleden een tekst door Google Translate haalde, zag het meteen. Gekke vertalingen, vreemde zinstructuren: daar was duidelijk iets mis. Vandaag is het verschil met een echte vertaler al kleiner. De dienst is er, schijnbaar op erg korte tijd, met rasse schreden op vooruit gegaan. Het verschil? Machine learning.
“AI is eigenlijk niet nieuw, ” zegt Mieke De Ketelaere, director Customer Intelligence West-Europa bij SAS, op een Straffe Madammen-avond over artificiële intelligentie. “Maar veel van die computerintelligentie werd vroeger geschreven met ‘als-dan’ regels. Dat is uiteindelijk heel zwakke intelligentie.” Waar Google Translate het vroeger moest hebben van taalregels die in code werden gegoten, is dat niet langer het geval. “AI is veel sterker als het gebaseerd is op ervaring”, zegt Mieke De Ketelaere. “Je leert een taal spreken door dialoog, en door ervaring kan je een systeem slimmer maken.”
Gezichtsherkenning gaat niet om blauwe ogen of bruin haar: voor een computer is een gezicht een reeks van 128 nummers
Het idee bij Machine learning is dat de computer zelf de logica invult, zonder dat alles op voorhand wordt uitgeschreven. “Een hond en kat uit elkaar houden, dat kan een kind van drie, ” zegt De Ketelaere. “Maar voor computers is dat moeilijk, want je kan dat niet in regels steken. Die dieren hebben allebei vier poten, een vachtje enzovoort. We hebben dat uiteindelijk aan computers geleerd door heel veel foto’s te taggen en ze vervolgens aan de computer te geven.”
Machine learning vs deep learning
Een computer trainen door hem een hele reeks gelabelde data geven, is de essentie van machine learning. Het is ook hoe ‘sterke AI’ wordt gemaakt. “Denk aan e-mails die je tagt, ” zegt De Ketelaere, “dit is spam, dit is geen spam. Of voor beelden: dit is een kasteel en dit niet. Na een tijdje gaat die computer in een status komen dat als je hem een nieuw beeld geeft, dat hij zelf kan aangeven of het een kasteel is of niet. Maar daarvoor heb je heel veel historische data nodig.” Enkele van de meest geavanceerde beeldherkenningstoepassingen zijn dan ook het resultaat van crowdsourcing, waarbij gebruikers worden ingezet om al het tijdrovende labelwerk te doen. “Een voorbeeld is de gezichtsherkenning van Facebook, ” zegt De Ketelaere, “elke keer dat jij een foto tagt, help je dat systeem mee trainen.”
Deep learning is dan de volgende stap, een subset van machine learning die gebruik maakt van verschillende lagen. Vaak gaat het dan om lagen die de data opdelen in makkelijker verwerkbare informatie. De Ketelaere geeft een simpel voorbeeld: “Voor gezichtsherkenning gaat men vectoren trekken van donkere naar lichte zones, zodat er ook met verschillende camerastandpunten rekening wordt gehouden. Het systeem gaat vervolgens landmarks zetten, zodat ze het beeld naar voor kunnen laten kijken. Tot slot gaat het proberen te herkennen wie het is. Het gaat dus om drie stappen, en uiteindelijk krijg je een code van 128 variabelen, uniek voor elke persoon. Gezichtsherkenning gaat dus niet om blauwe ogen of bruin haar: voor een computer is een gezicht een reeks van 128 nummers.”
Deep learning is op die manier één mogelijke techniek van velen, legt professor Danny De Schreye uit, coördinator van het masterprogramma artificiële intelligentie aan de KU Leuven. “In machine learning heb je heel wat families en verschillende aanpakken, ” zegt hij. “Essentieel kan je ze opdelen in subsymbolische en symbolische aanpakken. Subsymbolische zijn artificiële neurale netwerken. Zo’n systeem is een ruwe imitatie van de werking van de hersenen. Daar tegenover staat een heel pak andere manieren: classificaties, decision trees, reinforcement learning enzovoort.”
Je dataset moet compleet zijn, die moet kwaliteitsvol zijn, en ja, je moet daar legaal eigenaar van zijn
Neurale netwerken
De versie die momenteel furore maakt is deep learning via neurale netwerken. Zoals de naam aangeeft, imiteert zo’n neuraal netwerk een menselijk brein, zegt De Ketelaere. “Het bestaat uit neuronen en de connecties daartussen. Als je leert, worden connecties tussen neuronen gemaakt en gaat het brein ook anticiperen op de volgende keer dat er zoiets langskomt.” Iets gelijkaardigs gebeurt in een artificieel neuraal netwerk. Het systeem gaat zelf lagen opbouwen en traint dus in principe ook zichzelf.
“Deep learning is een wiskundig model. Er komt data in, er gaat data uit en daartussen zitten een hele hoop knopjes die je kan ‘tunen’. Om je systeem te trainen heb je die data nodig, dat wiskundige model, en een leerregel die zegt ‘dat komt eruit, en dat wil ik dat eruit komt’. Als daar een fout tussen zit, wordt die fout gebruikt om aan de knopjes te draaien en het systeem opnieuw af te stellen, ” legt professor Joni Dambre uit. Zij is professor aan de UGent en lid van IDLab, een van de onderzoeksgroepen van Imec.
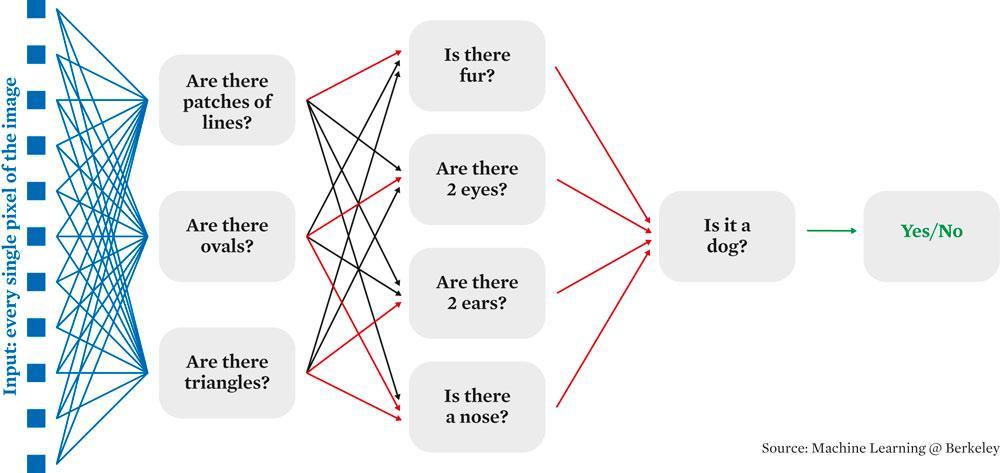
En waren het bij oudere machine learning systemen nog mensen die aan de knopjes draaiden, dan is dat bij neurale netwerken anders. “Oudere systemen werden beperkt door de slimheid van de mensen die die features moesten bedenken. Daarom gaat een neuraal netwerk die zelf zoeken, door allemaal lagen aan te maken. Wanneer je data binnenkomen, bijvoorbeeld de pixels van een beeld, dan worden die naar een aantal neuronen gestuurd, die daar een kleine berekening op uitvoeren en ze weer doorsturen naar de volgende laag. Daar wordt al die data weer gemengd, en weer. Laag na laag, ” aldus Dambre. “Uiteindelijk gaat het leeralgoritme zelf aan al die knopjes draaien, en dat kunnen er miljoenen zijn, om het model af te stellen. En dan kan je visualisatietechnieken toepassen en bijvoorbeeld ontdekken dat het ene neuron iets leert herkennen dat lijkt op een bloemetje, en een ander neuron dierenvacht gaat herkennen.”
Black box
Een neuraal netwerk is dus niet altijd een ‘black box’ waarin u data invoert en weer uit haalt, zonder dat het helemaal duidelijk is waarom het systeem u die data geeft. Al heeft dat mysterie veel met het soort model te maken, zegt De Schreye: “Mensen die het gebruiken in natuurlijke taal zeggen mij dat ze geen enkele idee hebben wat er in de lagen gebeurt. Er komt niets overeen met wat zij met hun theorieën over taal herkennen.”
Bij beeldherkenning wordt dat iets makkelijker, zegt Dambre: “Er zijn manieren om te visualiseren waar zo’n neuron op reageert. En dan kan je bijvoorbeeld zien dat er in de tweede laag van zo’n beeldherkenningssysteem bijvoorbeeld eentje reageert op ronde vormen, en vind je in verdere lagen neuronen die reageren op patronen als honingraten. Als je nog verder gaat kijken zie je bijvoorbeeld ogen of gezichten. Die eigenschappen waar een neuron op reageert, die worden per laag complexer. Dus dat gaat echt van simpele dingen zoals lijnen of hoeken, naar gezichten, handen enzovoort. En op het einde krijg je bijvoorbeeld een honddetector als een van die ‘neuronen’, of een autodetector, of een mensdetector.”

Onder de motorkap
Zo’n complexe systemen, dat vereist computerkracht. Het is dan ook niet toevallig dat neurale netwerken net nu een opvallende groei kennen, zegt De Schreye: “De omvang van die netwerken is enorm vergroot, en de hoeveelheid voorbeelden die ingevoerd worden, nemen erg grote proporties aan. Dankzij de versnelde rekenkracht kan je daar effectief massale hoeveelheid training invoeren. En daardoor kan je taken oplossen die je vroeger niet kon oplossen. Omdat vroeger de capaciteit niet groot genoeg was. ”
Daar komt bij dat de technologie op dit moment redelijk matuur is geworden, zegt professor Joni Dambre. “De technologie voor bijvoorbeeld deep learning begint stabiel te worden. En dus komen er ook meer tools uit. Je hebt bijvoorbeeld platformen als Keras, die het makkelijker maken om een deep learning systeem te bouwen. Eens je weet welke architectuur je wilt maken, is dat een paar lijntjes code. De moeilijkste dingen zitten verborgen onder de motorkap.”
Waar vroeger een bedrijf voor machine learning en zeker deep learning een consultant als SAS nodig had, kan een beetje ICT’er er nu, voor goed-afgelijnde projecten, zelf aan beginnen. Al waarschuwen de experten ook meteen voor de gevaren.
Crap in, crap out
Wie het nieuws een beetje volgt, kent namelijk voorbeelden genoeg van AI’s die vooringenomen, racistische of seksistisch zijn. In de meeste gevallen is de schuldige te zoeken bij de datasets waarmee deze AI’s getraind zijn. “Heel veel hangt af van de input waarop je traint, ” zegt De Ketelaere. “Alexa herkende in het begin bijvoorbeeld geen kinderstemmen. Soms gaat beeldherkenning mensen van minderheden niet herkennen. Dat krijg je als de database niet volledig is. Crap in, crap out. Je dataset moet compleet zijn, die moet kwaliteitsvol zijn, en ja, je moet daar legaal eigenaar van zijn”, zegt ze, met een knipoog naar Cambridge Analytica.
Het is de verantwoordelijkheid van degene die het systeem traint, om te zorgen dat die data representatief is. Dat daar geen bias op zit
Het bekendste voorbeeld van dat ‘crap in, crap out’ principe is waarschijnlijk Tay, de chatbot die Microsoft op Twitter losliet, en die daar al snel fan werd van Hitler. “Als je chatbots traint op basis van berichten waar veel racistische dingen in zitten, dan gaat ie dat nadoen, ” zegt Dambre. “Dat is namelijk wat ie geleerd heeft. ‘Je zegt mij: als ik dat zie, dan moet dat eruit komen, en ik ga dat zo goed mogelijk nabootsen.'” Tay is dan ook vooral een voorbeeld van hoe het niet moet. “Meestal wordt deep learning gebruikt als een vorm van gesuperviseerd leren, ” zegt Dambre. “In de trainingdata moet elk voorbeeld een label hebben, en de data moeten representatief zijn. Wil je dat je AI vossen leert kennen, dan moet je hem vossen geven, en ook beelden waar geen vossen op staan. Het is de verantwoordelijkheid van degene die het systeem traint, om te zorgen dat die data representatief zijn. Dat daar geen bias op zit.”
Een ander voorbeeld van waar het mis kan gaan komt van Dr. Sameer Singh, van de University of California. Hij gebruikte een neuraal netwerk om wolven van husky’s te leren onderscheiden. Dat netwerk produceerde onverwacht goede resultaten, tot bleek dat het een short-cut had gevonden. Analyse toonde aan dat het netwerk zichzelf niet aan het trainen was op gezichten van de dieren of de specifieke vorm van de staart, maar op de achtergrond. Husky’s stonden meestal in een sneeuwlandschap. Dus sneeuw betekende, voor het netwerk, husky. “Op zich is zo’n systeem vrij dom, ” zegt Dambre, “het gaat de simpelste manier vinden om een verband te geven. Dus moet je zorgen dat als jij dat systeem traint, je ook genoeg tegenvoorbeelden geeft.”
Daarom is de testfase minstens even belangrijk als de leerfase. Voor machine learning moet elke dataset in twee worden geknipt, zegt De Ketelaere. “Een set om te trainen en eentje om te testen. Zo kan je zien dat het systeem het juist heeft en weet je dat als je het nieuwe data geeft, waarvan jij ook niet weet wat het is, dat het dat dan juist kan herkennen. Je moet dat vertrouwen hebben dat hij het kan.”
Hoe leidt u een AI om de tuin?
Opvallend onderzoek aan de universiteit van Berkeley. Daar werken studenten aan manieren om verborgen ‘bevelen’ in muzieknummers te steken, die een assistent als Alexa zou opvolgen wanneer ze de muziek afspeelt. Eerder hadden Chinese studenten al een manier gevonden om bevelen in ruis te verwerken. Het zijn voorbeelden die het lab nog niet uit zijn, maar ze tonen wel aan dat iemand met enige vindingrijkheid een AI om de tuin kan leiden. “Deep learning is een model dat ongelooflijk krachtig is, ” verklaart Dambre. “Het kan bijna om het even welk verband tussen data in en data out nabootsen. Om goed te werken, moet je het zelfs redundant maken, zodat er heel veel manieren zijn om dat verband te realiseren. Dat is ook de reden dat ze soms gemakkelijk bedot kunnen worden.” Nog zo’n voorbeeld is het ‘tweaken’ van foto’s. Dezelfde foto van een panda kan zo met wat extra pixels terug ingevoerd worden in het systeem, en ‘herkend’ worden als een gibbon aap. “Met dezelfde trainingstechnieken die je gebruikt om het model af te stellen, kan je de input een klein beetje kan veranderen, zodat het systeem daar een andere uitkomst in ziet. Terwijl wij het verschil niet zien tussen die twee beelden.” Ook daar wordt trouwens aan gewerkt. “Er gebeurt veel onderzoek naar dat ‘adversarial effect’, maar op dit moment zijn de meeste onderzoekers het erover eens dat dit niet kan vermeden worden als je met zulke krachtige netwerken werkt. Je kan het verminderen, maar je krijgt het niet weg.”