
Voor het eerst is een AI-bot erin geslaagd om vijf pokerkampioenen tegelijk naar huis te spelen. Dat beschrijven onderzoekers van Carnegie Mellon University in het wetenschappelijke tijdschrift Science.
Dammen, schaken, Go: de voorbije jaren slaagde artificiële intelligentie erin om menselijke kampioenen te verslaan in spelletjes van toenemende complexiteit. Alleen poker werd lang gezien als een onneembare vesting. Succes hangt er immers af van het toeval en van hoe goed je kan bluffen. Dat laatste is niet meteen iets wat je van een computer verwacht. Bij dammen, schaken of Go kan iedere speler bovendien het volledige spelbord kan overzien. Poker daarentegen is een spel met onvolledige informatie: je weet niet welke kaarten je tegenspeler in de hand heeft.
Traditioneel pakt de speltheorie zulke situaties aan door naar een ‘Nash-evenwicht’ te zoeken. Bij een spelletje ‘blad, steen, schaar’ lijkt zoiets nog eenvoudig te vatten: je weet niet wat de ander zal doen, dus kan je maar best willekeurig voor ‘blad’, ‘steen’ of ‘schaar’ kiezen. Je tegenspeler kan hoogstens evengoed doen door voor dezelfde strategie te opteren. Merk je na verloop van tijd dat de andere systematisch meer dan één op de drie keer voor ‘blad’ kiest? Dan kan je die zwakheid proberen uitbuiten door zelf wat meer voor ‘schaar’ te kiezen.
Bij poker maak je gelijkaardige afwegingen, maar dan op een complexer niveau. Goede kaarten op je hand? Best hoog inzetten. Anderzijds: zet je enkel hoog in als je goede kaarten hebt, dan beseffen je tegenspelers al snel dat ze niet moeten meegaan in het opbod. De kunst bestaat er dus in om onvoorspelbaar te blijven en op geschikte momenten eens te bluffen. Welke beslissing je wanneer neemt hangt tegelijk ook af van de beslissingen van je tegenspeler. Hiervoor een Nash-evenwicht berekenen wordt al snel onmogelijk, zeker als er meerder spelers aan de pokertafel zitten.
De Fin Tuomas Sandholm probeert al jaren om een computer met dit probleem te laten omgaan. Hij is verbonden aan Carnegie Mellon, een universiteit in Pittsburgh die aan de wereldtop staat op vlak van artificiële intelligentie. Twee jaar geleden ontwikkelde Sandholm samen met zijn doctoraatstudent Noam Brown een AI-bot die ze ‘Libratus‘ doopten. Dit programma slaagde erin om vier professionele spelers te verslaan in Texas Hold’em, de meest gespeelde pokervariant. Kanttekening daarbij: die pokerkampioenen werden niet tegelijk verslagen: Libratus slaagde er enkel in om spelletjes te winnen tegen één speler. Wanneer extra spelers aanschoven aan de pokertafel, werd het probleem te complex voor de AI-bot.
Daarom bouwden Sandholm en Brown een nieuwe pokercomputer: ‘Pluribus’. Die lieten ze eerst acht dagen tegen kopieën van zichzelf spelen. Dat deden ze zonder Pluribus vooraf in te lichten over hoe mensen poker spelen. Deze methode is gelijkaardig aan degene waarmee Google Deepmind-onderzoekers Alpha Go Zero creëerden (de laatste en meest succesvolle versie AI-computer die iedereen naar huis speelt in het bordspel Go). Ze heeft als voordeel dat de computer geen tunnelvisie of andere menselijke beperkingen aangeleerd krijgt.
Wanneer Pluribus zichzelf genoeg getraind had, mocht hij het opnemen tegen dertien verschillende professionele pokerspelers, waarvan er iedere dag vijf plaats namen aan de digitale pokertafel. In totaal werden tienduizend spelletjes Texas Hold’em unlimited afgewerkt. Pluribus verloor af en toe flink wat fiches. Poker blijft immers een spel waarin je een dosis geluk kan gebruiken. Naarmate meer spelletjes gespeeld werden, kwam de superioteit van Pluribus echter duidelijker naar boven. De computer deed het uiteindelijk signifcant beter dan zijn menselijke tegenstrevers. Er werd niet voor geld gespeeld, maar mocht elke pokerfiche 1 euro waard geweest zijn, dan zou Pluribus 5 euro per spel gewonnen hebben. Daarmee zouden de ontwikkelaars zo’n duizend euro per uur verdiend hebben.
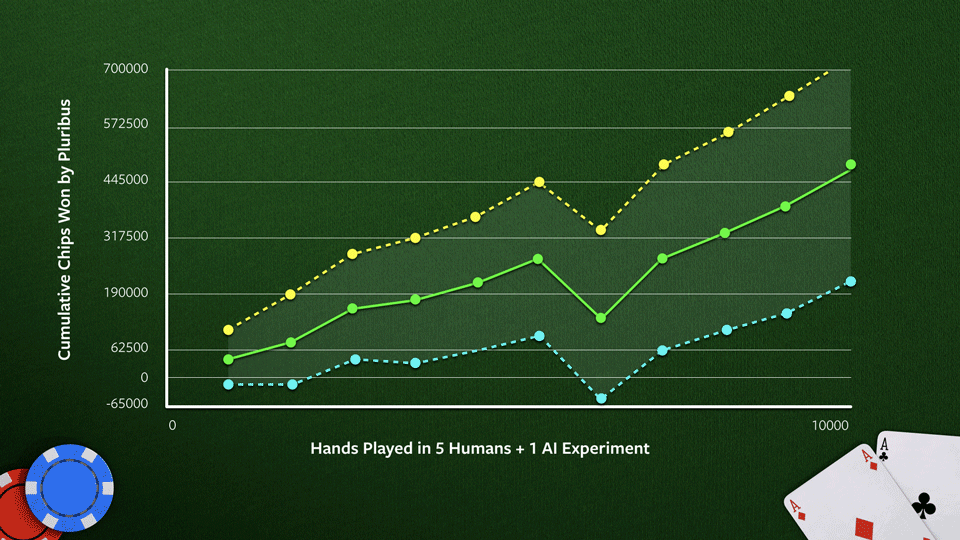
Daar staat overigens geen hoge computationele kost tegenover: Pluribus kreeg zijn basisvaardigheden aangeleerd in acht dagen, zonder gebruik van GPU’s. 512 GB RAM en 150 dollar aan cloud computing-kosten volstaan, zo beweert Noam Brown in een blog. Dit staat in schril contrast met andere recente AI-doorbraken, die gewoonlijk miljoenen dollars kosten om te trainen. “Sommige deskundigen in het veld zijn bezorgd dat toekomstig AI-onderzoek zal worden gedomineerd door de grote onderzoeksteams die als enige beroep kunnen doen op extreem veel computerkracht. Pluribus levert volgens ons het bewijs dat baanbrekend AI-onderzoek ook mogelijk is met bescheiden middelen”, schrijft Brown, die sinds kort ook voor Facebook werkt.
De onderzoekers hebben dus een goedkope robot gecreëerd die potentieel misbruikt kan worden om online casino’s op te lichten. “Dit kan zeer gevaarlijk zijn voor de poker-community”, geeft Brown toe aan Technology Review. In overleg met Sandholm besloot hij om de volledige code achter Pluribus niet vrij te geven.
Deze wetenschappelijke doorbraak kan ook implicaties hebben buiten het pokerspel. Volgens de onderzoekers kan gelijkaardige technologie ingezet worden voor pakweg verkeersnavigatie of cybersecurity. Bij zowat alle interacties neem je immers beslissingen op basis van onvolledige informatie en moet je rekening houden met de mogelijke intenties van meerdere partijen. Ook politieke onderhandelingen lijken in die zin veel meer op pokeren dan op schaken. Wie weet kan artificiële intelligentie onze politici in de toekomst helpen om een regering te vormen.